



Le 18 octobre dernier, le Groupe de travail de l’article 29 (G29), réunissant l’ensemble des autorités de contrôle des Etats membres de l’Union européenne en matière de protection des données à caractère personnel, publiait deux nouvelles séries de lignes directrices, dont l’une, attendue avec impatience par bien des acteurs du monde numérique, se penche enfin sur la fameuse question du profilage et des prises de décision automatisées.
Ce sujet présente, il est vrai, peut-être plus que tout autre dans le nouveau règlement général sur la protection des données (GDPR), un caractère éminemment actuel : les progrès récents et continus de l’intelligence artificielle permettent à bon droit de penser que de plus en plus d’aspects de la vie du citoyen et du consommateur moyen pourront à court ou moyen terme être intégralement pris en charge par des algorithmes de traitement de plus en plus complexes.
Dans ces conditions, le risque est de voir l’asymétrie s’aggraver toujours plus entre le responsable du traitement, concepteur ou commanditaire de l’algorithme, qui en détermine la logique et les objectifs, et la personne concernée, incapable de comprendre les conditions dans lesquelles ses données sont traitées et les décisions qui la concernent sont prises. A cet égard, le nouveau règlement, qui se donne pour principe fondamental celui du contrôle des individus sur leurs données (considérant 7), met l’accent sur l’obligation essentielle de transparence du traitement : tout traitement de données à caractère personnel doit être conçu et entrepris dans des conditions permettant aux personnes concernées d’en comprendre les tenants et les aboutissants, afin précisément de pouvoir exercer utilement le contrôle de leurs données, dans les conditions prévues par le texte lui-même. La CNIL n’a d’ailleurs pas attendu pour faire usage de ce fondement, en mettant en demeure le Ministère de l’Enseignement Supérieur, fin septembre dernier, pour son tant redouté système “Admission Post-Bac”.
C’est donc en toute logique que le règlement insère, aux côtés des modalités déjà bien connues de l’obligation d’information mise à la charge du responsable de traitement, de nouvelles dispositions spécifiques au profilage et à la prise de décision automatisée. Ainsi des articles 13.2.f et 14.2.g, relatifs respectivement à l’information à fournir aux personnes concernées selon que les données ont été collectées ou non directement auprès d’elles :
En plus des informations visées au paragraphe 1, le responsable du traitement fournit à la personne concernée […] les informations complémentaires suivantes qui sont nécessaires pour garantir un traitement équitable et transparent : […] l’existence d’une prise de décision automatisée, y compris un profilage, visée à l’article 22, paragraphes 1 et 4, et, au moins en pareils cas, des informations utiles concernant la logique sous-jacente, ainsi que l’importance et les conséquences prévues de ce traitement pour la personne concernée.
Parmi différentes manières d’encadrer le profilage et les prises de décision automatisées (que nous n’analyserons pas en détails ici), le règlement prévoit donc une obligation d’information renforcée, comprenant notamment “des informations utiles concernant la logique sous-jacente, ainsi que l’importance et les conséquences prévues [du] traitement“. Dans quels cas, cependant, cette information est-elle requise ? Qu’est-ce en effet qu’un “profilage” ou une “prise de décision automatisée” au sens du GDPR ? Et, surtout, quel est le contenu exact de l’information à fournir, lorsqu’elle est requise – comment, en deux mots, expliquer l’algorithme ? Les lignes directrices du G29 permettent de répondre à certaines de ces interrogations ; pour d’autres, un certain flou demeure, qui invite à imaginer ensemble les bonnes pratiques de demain.

Profilage et prise de décision automatisée : un régime à deux niveaux
A bien y regarder, la place du profilage dans l’économie des dispositions précitées, et plus généralement du règlement tout entier, apparaît pour le moins ambiguë. D’un côté, la notion se voit enfin juridiquement consacrée par l’introduction d’une définition, à l’article 4.4, qui capture en substance tout traitement automatisé de données à caractère personnel (sans considération du degré de complexité de ce traitement, ni du volume ou de la diversité des données traitées) ayant pour but d’évaluer certains aspects propres à une personne physique :
Toute forme de traitement automatisé de données à caractère personnel consistant à utiliser ces données à caractère personnel pour évaluer certains aspects personnels relatifs à une personne physique, notamment pour analyser ou prédire des éléments concernant le rendement au travail, la situation économique, la santé, les préférences personnelles, les intérêts, la fiabilité, le comportement, la localisation ou les déplacements de cette personne physique.
D’un autre côté, pourtant, force est de constater, au regard du texte des articles 13.2.f et 14.2.g précités, relatifs à l’obligation d’information renforcée, que le profilage ne fait véritablement l’objet d’une réglementation spécifique que dans l’hypothèse et dans la mesure où il aboutit à une “prise de décision automatisée” au sens de l’article 22 du texte, à savoir “une décision fondée exclusivement sur un traitement automatisé, y compris le profilage, produisant des effets juridiques [vis-à-vis de la personne concernée] ou l’affectant de manière significative de façon similaire“. Cette dernière formule (plus rigoureuse que celle, quelque peu maladroite, des articles 13.2.f et 14.2.g eux-mêmes – “une prise de décision automatisée, y compris un profilage“) confirme en effet que le profilage n’est que l’une des formes de traitement automatisé permettant d’aboutir à la prise de décision automatisée, vraie pierre de touche de la réglementation.
Il y a donc profilage et profilage, et l’on s’attachera donc, pour bien identifier les règles applicables, non pas tant à la nature ou à la complexité du traitement lui-même, qu’à son issue (une prise de décision “produisant des effets juridiques [vis-à-vis de la personne concernée] ou l’affectant de manière significative de façon similaire“) et à l’intervention ou non, dans cette issue, d’un agent humain (une prise de décision “automatisée“). Les lignes directrices du G29 sont à cet égard très claires, en ce qu’elles distinguent radicalement entre deux régimes : un régime spécial, d’abord, applicable au profilage qui aboutit à une prise de décision automatisée au sens de l’article 22, mais aussi à tout autre traitement automatisé de données qui aboutit à une telle prise de décision (Chapitre III des lignes directrices) ; un régime plus général, ensuite, applicable lorsque le profilage n’aboutit pas à une prise de décision automatisée au sens de l’article précité (Chapitre IV des lignes directrices).
Pour ce qui concerne l’obligation d’information renforcée, cette distinction n’est pas sans importance. Un profilage peut en effet être mis en oeuvre sous le contrôle d’un agent humain, comme par exemple dans le cas d’un algorithme de scoring utilisé à titre informatif par un conseiller bancaire. D’autre part, un profilage peut être mis en oeuvre sans pour autant “produi[re] des effets juridiques [vis-à-vis de la personne concernée] ou l’affect[er] de manière significative de façon similaire“, comme le reconnaît le G29 lui-même, dans le cas par exemple du profilage à des fins de publicité ciblée en ligne. Dans ces deux cas, une application rigoureuse des articles 13.2.f et 14.2.g semble conduire à écarter toute obligation d’information “concernant la logique sous-jacente, ainsi que l’importance et les conséquences prévues [du] traitement” : pas de “prise de décision automatisée” au sens de l’article 22, pas d’obligation d’information renforcée ! Tout au plus le texte invite-t-il timidement le responsable de traitement à choisir de fournir ces informations même en l’absence de prise de décision automatisée, comme une faveur faite à la protection des données (“au moins en pareils cas“).
Le G29 se veut cependant un peu plus exigeant, en rappelant que l’obligation de transparence impose dans tous les cas de fournir toutes les informations pertinentes à la personne concernée relativement à la nature du traitement de ses données, quand bien même le texte ne préciserait pas exactement la teneur de ses informations ; les lignes directrices citent notamment le considérant 60 du règlement, lequel indique, au titre de cette obligation de transparence, que “la personne concernée devrait [toujours] être informée de l’existence d’un profilage et des conséquences de celui-ci“, c’est-à-dire même dans les cas où ce profilage n’aboutirait pas à une prise de décision automatisée. Du reste, le Groupe de travail renvoie à l’adoption prochaine de nouvelles lignes directrices, dédiées précisément à la mise en oeuvre de ces obligations générales de transparence et d’information ; gageons que celles-ci viendront éclairer cette “zone grise” du “simple” profilage (sans prise de décision automatisée), en précisant le contenu de l’information exigée en pareil cas.
En l’état actuel, il semble du moins possible de synthétiser la situation comme suit, pour le responsable de traitement qui se trouverait quelque peu perdu au milieu de toutes ces notions (on le comprend) :
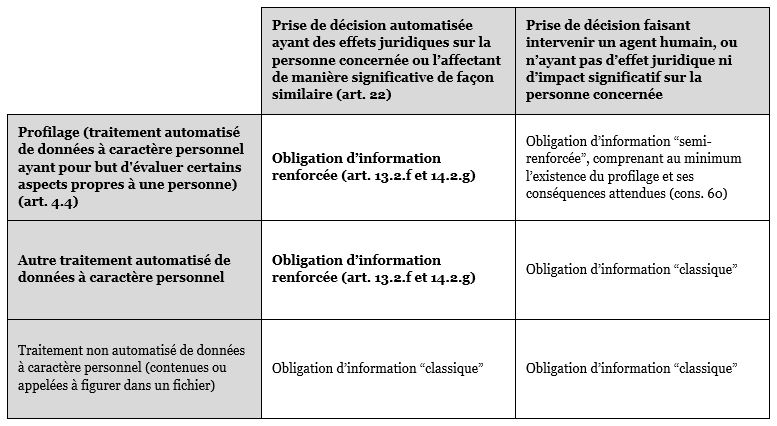
Tout ceci bien en tête, reste cependant le gros de la question : que contient donc cette fameuse obligation d’information renforcée ? Comme indiqué, il s’agit de fournir “des informations utiles concernant la logique sous-jacente, ainsi que l’importance et les conséquences prévues [du] traitement“. Si, dans les cas les plus banals (le champ d’application de cette obligation étant, comme on l’a vu, indifférent à la complexité des traitements mis en oeuvre), ces informations ne devraient pas être trop difficiles à verbaliser, un lourd obstacle pratique risque en revanche de se poser à l’égard des traitements qui mettent en jeu de puissants outils algorithmiques, et à plus forte raison encore des mécanismes d’intelligence artificielle de type machine-learning. Comment, dans ce cas, assurer une information valable sur la “logique sous-jacente du traitement” ? Faudra-t-il aller jusqu’à dévoiler aux personnes concernées les codes sources de ces outils et de ces mécanismes ?

Informer ni trop, ni trop peu : la proposition d’une approche fonctionnaliste
Probablement pas. Une information fondée sur la divulgation des algorithmes de traitement, outre qu’elle paraît difficile à mettre en oeuvre, ne semble en effet pas nécessaire au regard des exigences du GDPR – elle serait même, dans la majorité des cas, contre-productive. Le G29 l’a d’ailleurs bien compris, qui adopte à cet égard une approche pragmatique :
The controller should find simple ways to tell the data subject about the rationale behind, or the criteria relied on in reaching the decision without necessarily always attempting a complex explanation of the algorithms used or disclosure of the full algorithm.
(Le responsable de traitement devrait trouver des manières simples d’indiquer aux personnes concernées la logique derrière la décision, ou les critères sur laquelle elle est fondée, sans nécessairement essayer de donner une explication complexe des algorithmes utilisés, ou divulguer l’intégralité de ces algorithmes.)
C’est qu’une telle divulgation, d’abord, se heurterait au respect du secret des affaires et de la propriété intellectuelle, dans un monde où l’actif immatériel que constitue un algorithme performant peut représenter l’essentiel de la valeur d’une entreprise ; le considérant 63 du règlement précise d’ailleurs lui-même, concernant le droit d’accès, que celui-ci “ne devrait pas porter atteinte aux droits ou libertés d’autrui, y compris au secret des affaires ou à la propriété intellectuelle, notamment au droit d’auteur protégeant le logiciel“.
Aussi, surtout, une retranscription intégrale de l’algorithme, voire son explication mathématique, est à l’évidence insusceptible de satisfaire aux conditions de clarté et d’accessibilité posées par le texte, dont l’article 12.1 dispose que l’information doit être donnée aux personnes concernées “d’une façon concise, transparente, compréhensible et aisément accessible, en des termes clairs et simples, en particulier pour toute information destinée spécifiquement à un enfant“. Dans de nombreux cas, ces exigences seront même doublées, en droit français, par celles de l’article 211-1 du Code de la consommation, selon lequel “les clauses des contrats proposés par les professionnels aux consommateurs doivent être présentées et rédigées de façon claire et compréhensible” – la politique de confidentialité d’un commerçant sur Internet s’analysant, au même titre que ses conditions générales, en un contrat conclu avec l’utilisateur-consommateur.
Une telle explication, intégrale et mathématique, n’aura de fait, paradoxalement, aucune valeur informative pour la moyenne des personnes concernées – à plus forte raison quand de nombreux experts demeurent eux-mêmes perplexes face au comportement de certaines intelligences artificielles auto-apprenantes (machine learning), soulevant par là même des doutes quant à la possibilité de recourir à certaines formes très avancées d’intelligence artificielle dans le cadre d’une prise de décision automatisée, lorsque le détail de leur raisonnement finit par échapper jusqu’à la compréhension de leurs concepteurs. L’écueil est donc, en cette matière, double et symétrique, en ce qu’il réside aussi bien dans un défaut d’information que dans un trop-plein d’information. Un récent article, cité par les lignes directrices du G29, développe en ce sens le concept de transparency fallacy, calqué sur celui de consent fallacy : de même que tous les observateurs s’entendent pour reconnaître que le consentement des personnes concernées est généralement donné sans véritable réflexion, comme une pure formalité, et partant dénué de la valeur décisive que les textes et les autorités de contrôle prétendent lui accorder (nous en donnions un exemple ici-même il y a peu, en matière de publicité ciblée sur Internet), de même une information surdétaillée, “à rallonge”, s’avère le plus souvent d’un intérêt purement illusoire.
Faut-il alors en déduire, comme semblent le faire les auteurs de cet article, que toute tentative d’information relative à des traitements algorithmiques serait, tout compte fait, peine perdue ? Rien n’impose, à notre sens, un tel défaitisme ; surtout, le G29 précise bien que la sophistication des traitements ne dispensera jamais de s’acquitter de l’obligation d’information imposée par le texte (“complexity is no excuse for failing to provide information to the data subject“). Il s’agit donc, en définitive, d’informer ni trop, ni trop peu – soit, mais au regard de quel étalon ? La meilleure approche nous semble être à cet égard une approche fonctionnaliste : l’information fournie doit être suffisante pour remplir les objectifs qui en dépendent, du point de vue de la protection des personnes concernées.
Ces objectifs sont selon nous bien identifiables, ne serait-ce qu’à la lecture du GDPR : l’obligation d’information vise à permettre aux personnes concernées, vis-à-vis d’un traitement de leurs données, (i) d’exprimer un consentement éclairé, lorsque le traitement a ce consentement pour condition de licéité (ou, plus indirectement, de consentir de façon éclairée à la conclusion d’un contrat, lorsque le traitement a ce contrat pour condition de licéité), et (ii) d’exercer utilement leurs différents droits.
Il devrait donc être possible, pour n’importe quel traitement, de déterminer les catégories d’informations à fournir en considération de ces deux objectifs. Parmi ces catégories d’informations, celles spécifiquement visées par l’obligation d’information renforcée dans le cas d’une prise de décision automatisée (“des informations utiles concernant la logique sous-jacente, ainsi que l’importance et les conséquences prévues [du] traitement“) nous paraissent particulièrement nécessaires (i) pour l’expression d’un consentement éclairé, ainsi que (ii) pour l’exercice du droit de rectification, du droit d’opposition, et du droit “d’obtenir une intervention humaine de la part du responsable du traitement, d’exprimer son point de vue et de contester la décision” (article 22.3). La personne concernée doit en effet disposer d’une information suffisante sur les règles du traitement qui sous-tend la prise de décision automatisée dont elle fera l’objet, pour choisir de se soumettre ou non à cette décision (consentement) ou pour refuser, a posteriori, d’y rester soumise (droit d’opposition) ; elle doit par ailleurs disposer de cette même information pour contester la décision prise (droit de contestation de l’article 22.3) ou l’exactitude des données utilisées et générées par l’algorithme (droit de rectification).
Aucun de ces objectifs, on le comprend, ne requiert absolument une explication mathématique de l’algorithme mis en oeuvre. Il s’agit plutôt, en général, d’informer sur la nature et les enjeux de la décision prise pour la personne concernée, sur les catégories de données à caractère personnel utilisées par l’algorithme, sur la pondération relative de chacun des critères sur lequel il se fonde, sur les mesures prises pour assurer la fiabilité des résultats, ou encore sur les recours ouverts pour contester la décision. Une explication plus détaillée des mécanismes mathématiques pourra être réservée pour ces hypothèses de recours, précisément, dans le cadre d’un échange contradictoire avec la personne concernée : celle-ci pourrait en effet demander à rencontrer un représentant du responsable de traitement (son conseiller bancaire, par exemple, dans le cas d’un algorithme de scoring), afin de se faire expliquer en détail les résultats obtenus, et choisir, sur cette base, de les contester effectivement ou non. Cette explication plus détaillée pourra notamment contenir, ainsi que le suggérait la Commission Nationale de l’Informatique et des Libertés (CNIL) dans un avis récent relatif à la loi pour une République numérique (obtenu et publié par Nextinpact), des informations relatives à la méthode ayant servi à développer l’algorithme, aux contraintes et aux besoins ayant guidé ce développement, aux taux d’erreur par catégorie de données, aux critères de test et d’évaluation, ou encore, “si l’algorithme est le produit d’un apprentissage machine, [aux] sources de données qui ont été utilisées pour [le] concevoir“.

Vers de nouvelles méthodes d’information : recentrer le discours sur les personnes concernées
Une approche en plusieurs étapes, ou plusieurs “couches”, en somme, selon les besoins de la personne concernée : voilà justement ce que semble recommander le G29, lorsqu’il cite à la fois l’autorité de contrôle australienne (“The very technology that leads to greater collection of personal information also presents the opportunity for more dynamic, multilayered and user centric privacy notices” – “Les mêmes technologies qui conduisent à une plus large collecte de données à caractère personnel offrent également la possibilité d’une information plus dynamique, multicouche et centrée sur l’utilisateur“) et l’article susmentionné.
Les auteurs de cet article, dans leur quête d’une méthode d’explication efficace des algorithmes à destination des personnes concernées, en arrivent à la conclusion que les solutions les plus prometteuses consistent dans des formes d’explication “exploratoires” et centrées sur leur destinataire (“exploratory, subject-centered explanations“). A ce stade, le droit doit donc ouvrir ses portes aux sciences cognitives et aux sciences de l’éducation : de même qu’il n’est pas nécessaire de maîtriser l’intégralité des règles de la mécanique avancée pour faire des choix raisonnables en matière d’achat et de conduite d’un véhicule, de même tout objet est susceptible de plusieurs niveaux d’analyse et d’explication, plus ou moins heuristiques selon les besoins concrets de celui qui demande cette explication. Il devrait donc être possible, face à un traitement algorithmique, de proposer une information à géométrie variable, depuis un niveau minimal (les principes du traitement) jusqu’à des niveaux plus détaillés – sans qu’il soit a priori nécessaire qu’aucun de ces niveaux implique la divulgation de l’algorithme lui-même.
Quant aux formes à donner à cette décomposition de l’information, il revient manifestement aux responsables de traitements de les imaginer – même si l’on peut raisonnablement espérer que les futures lignes directrices du G29, dédiées aux obligations de transparence et d’information, offriront quelques idées sur ce point. Il pourrait s’agir, au plus simple, de text boxes déroulables ; il pourrait s’agir aussi, comme le propose l’article précité, de simulateurs en ligne, permettant à la personne concernée de “tester” les règles de l’algorithme ; il pourrait s’agir, encore, de chatbots, l’intelligence artificielle proposant elle-même d’expliquer les raisons de ses choix, sur un mode conversationnel. Surtout, une explication humaine, discursive, contradictoire, devrait à notre sens rester accessible, comme dans l’exemple précédent du conseiller bancaire ; la dimension contradictoire apparaît en effet au coeur des préoccupations qui sous-tendent le GDPR vis-à-vis des prises de décision automatisées, à travers l’exigence de “mesures appropriées pour la sauvegarde des droits et libertés et des intérêts légitimes de la personne concernée, au moins du droit de la personne concernée d’obtenir une intervention humaine de la part du responsable du traitement, d’exprimer son point de vue et de contester la décision“.
Si tout reste à inventer, il importe donc en tous cas, plus que jamais, de privilégier l’explication à l’information brute, et, surtout, d’oublier les notices “Informatique & Libertés” stéréotypées, pour leur préférer des interfaces user-friendly, ou plutôt reader-centered. En un mot : keep it simple, silly !
Un grand merci de l’auteur de ces quelques lignes est adressé à Gabriel Lecordier, pour le partage de ses intuitions sur ce sujet complexe et passionnant.



une approche intéressante, sujet pourtant complexe à appréhender au premier abord, merci pour vos lumières M. Aulas
Merci Charlie pour ce retour de lecture – ravi de voir que nos articles contribuent à éclaircir ces questions effectivement complexes, et passionnantes ! N’hésitez pas à parcourir nos autres publications, et à très vite sur Aeon !
Hello,
Juste pour signaler l’existence de ce paper sur l’explicabilité https://dltr.law.duke.edu/2017/12/04/slave-to-the-algorithm-why-a-right-to-an-explanation-is-probably-not-the-remedy-you-are-looking-for/
Par ailleurs, quel est ton sentiment sur la possibilité d’avoir une tierce personne qui soit en charge de l’explicabilité ? Si ça pose des questions en termes de protection intellectuelle et tutti quanti, dans la mesure où les exigences légales sont font de plus en plus sérieuses concernant le devoir d’explicabilité d’une entreprise, il me semble raisonnable de penser que cela devienne une expertise et un business à part entière. Est-ce que tu vois une potentielle barrière au développement de cette économie ?
Merci Paolo – le paper en question est cependant linké dans l’article lui-même ! 😉 Concernant ton observation, elle me paraît très juste et le GDPR ne semble en rien exclure la “sous-traitance” de l’exécution de l’obligation d’information. Au contraire : une information efficace peut mobiliser des compétences de présentation visuelle, p. ex. des infographies, interfaces ou vidéos, qu’un responsable de traitement n’aura pas forcément en interne. Un nouveau coeur d’activité pour les agences de comm peut-être ? 🙂
Bonjour, quel est votre opinion sur la concordance entre la GDPR et le secret bancaire ? Il y a quelque part une certaine opposition.
Bonjour Florent,
Merci pour votre lecture et votre commentaire ! Le GDPR prévoit la prise en compte du secret professionnel à différents niveaux, notamment en laissant aux Etats membres une assez large marge de manoeuvre pour régir les relations entre les responsables de traitement soumis à une telle obligation de secret et les autorités de contrôle de la protection des données à caractère personnel. Peut-être avez-vous à l’esprit une hypothèse qui présenterait un risque de contradiction en particulier ? Je serais ravi d’en discuter plus avant le cas échéant.